ChatUI
December 2023
A React web interface for Llama2 LLMs, à la ChatGPT.
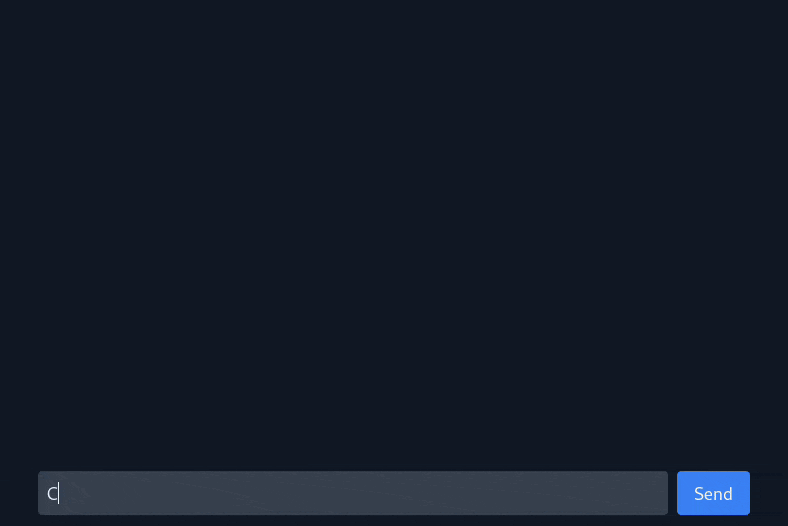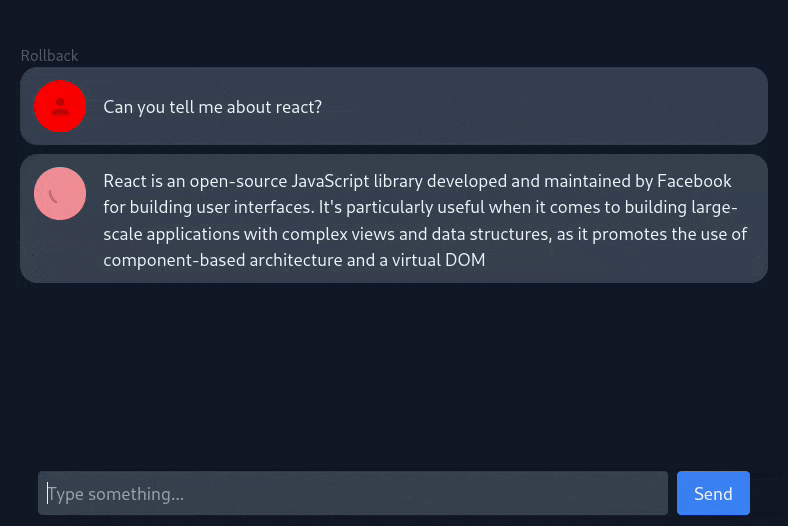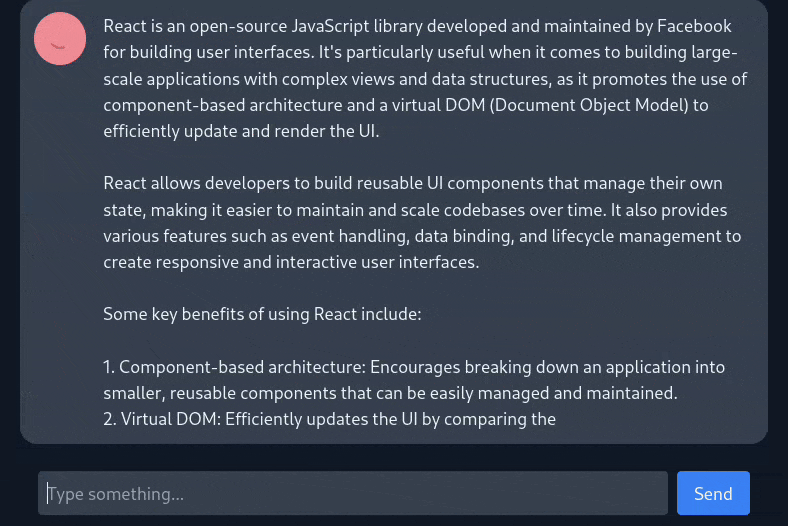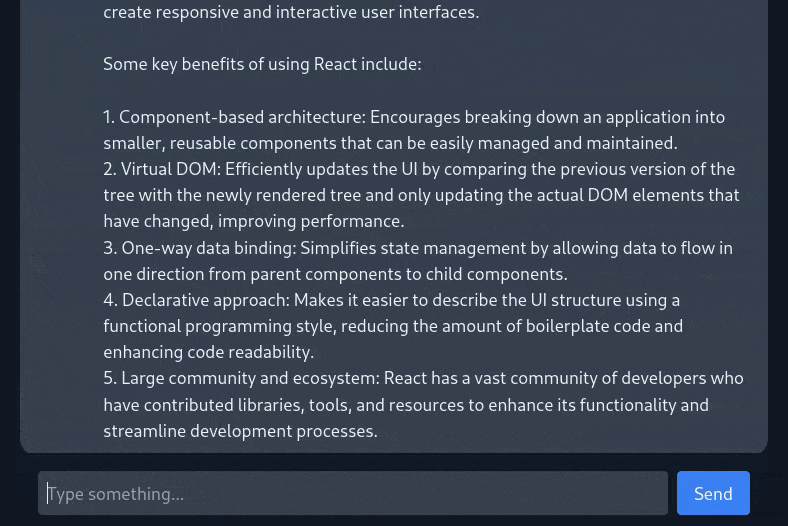
I’m a big fan of local LLMs, and I’ve been experimenting with them via tools like Ollama and llama.cpp for a while now. However, I found it a bit annoying to use the command line to interact with them. Therefore, I wanted to create a web interface that would allow me to easily interact with LLMs from my browser instead, while giving me a chance to build something useful with React in the process. Thus, ChatUI was born.
Due to the application’s simplicity and lack of routing, I decided to use raw React instead of a framework like Next.js. The UI is styled using TailwindCSS, which works well with JSX/TSX and offers a lot of flexbox-related functionality that I made heavy use of. Finally, the app is bundled using Vite and SWC, which allow for fast builds and hot module reloading.
The app communicates via REST with a dockerized instance of Ollama, which handles downloading and running LLMs. Streaming responses from Ollama as they are generated was a bit tricky, but I was able to get it working by building an async generator function that wraps the Ollama API call and yields each fragment of the response as they are generated. Each message’s iterable is passed as a prop into its corresponding chat bubble component, which uses a for await loop to consume response fragments as they are generated and display them on the screen. This gives the impression that the model is typing out its response in real time, and allows for some nice animations as the chat bubbles expand to fit the new lines.
I also put a lot of thought into the icons that are displayed next to each message. When the model is generating a response, a spinner is displayed to indicate that it is still working and to bring the user’s attention to the new chat bubble. Once the response is generated, the spinner is replaced with an icon that represents the model that generated the response – by default this is the first letter of the model’s name, but it can also be configured manually. An error icon and message are displayed in lieu of the response if an API call fails, and an option is given to let the user retry their request.
Because of Ollama’s Modelfile functionality and the large number of models that are available in the Llama ecosystem, I also eventually want to make switching between them easier. I already query the available models and display them on a sidebar, but this still needs to be made interactive and connected to the logic that generates the responses. I also want to look at persisting chat logs and switching between them, as well as a means of configuring the system prompt and other model parameters for each individual chat.